
Integrating data from diverse, heterogeneous systems is essential for meaningful use of available data, but this requires an effective means of linking records. The goal of record linkage (RL) is how to match rows in multiple tables that represent the same real world entity. Also called entity resolution, record linkage allows identifying the same real world entity in multiple databases (record linkage) as well as in a single database (de-duplication). Key challenges are the lack of a common, error-free, unique identifiers across data sources and the need to use patient-level identifying information to ensure proper linkage. Accurate record linkage is critical for building data research networks and replicable science.
While automated methods can help integrate many records from heterogeneous data systems, high-quality record linkage requires human interaction to manage the inevitable errors and discrepancies resulting from imperfect and complex real world data. Errors that are not properly managed in machine-only data integration systems propagate to subsequent data analyses, which can lead to potential problems with invalid results and poor decision making. Thus, researchers need a means of providing direct control over the record linkage process to limit and bound errors. However, due to the personal and often sensitive nature of human data, privacy becomes a serious concern. The goal of this research is to investigate secure techniques and develop effective tools to accurately integrate heterogeneous data while still protecting human confidentiality by using a hybrid human-machine system that securely and strictly controls information disclosure.
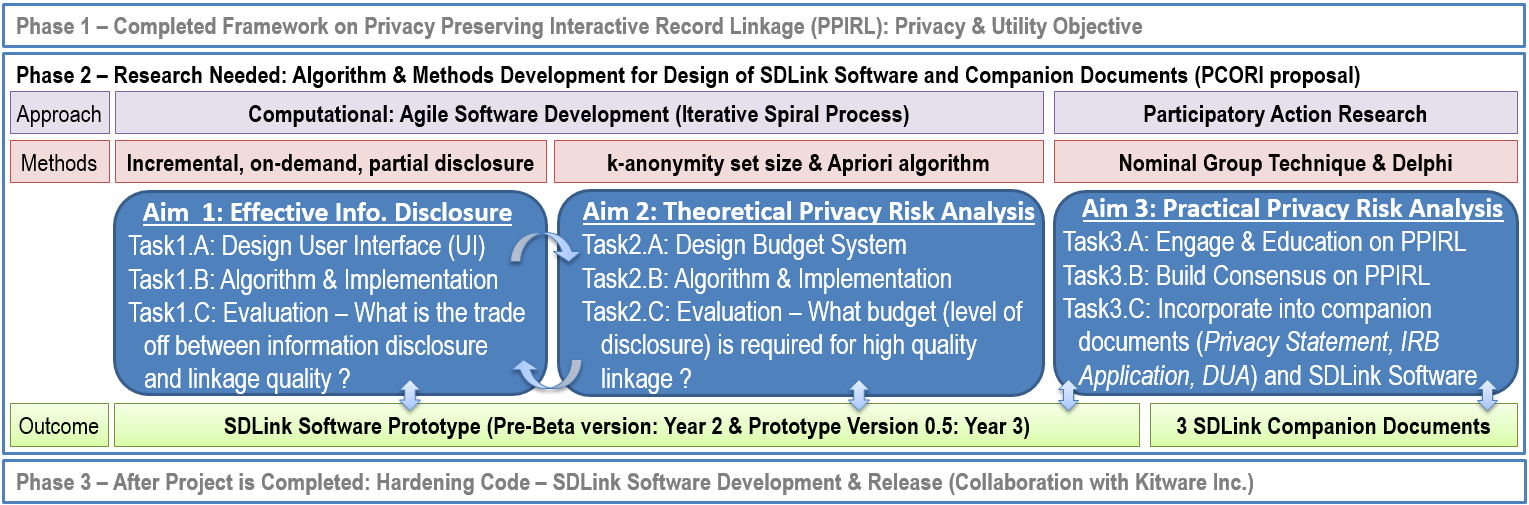
This study focuses on improving 1) methods to support data research networks, 2) methods to improve the validity and replicability of data-intensive studies, and 3) research related to the ethical conduct of PCOR/CER. The long-term goal in PPIRL research is to develop open source software, documentation, and training material that allow users to securely and accurately integrate biomedical data from heterogeneous systems to support PCOR/CER (Fig B2 Phase 3). Our preliminary results indicate that we can guarantee against sensitive attribute disclosure by decoupling (i.e., separating the identifying information from the sensitive information) and chaffing (i.e., adding fake data). We now need to investigate how to minimize the identity disclosure while still obtaining high quality record linkage and quantify any remaining risks. In so doing, we can properly inform all stakeholders of this risk. Our central hypothesis is that there is a level of identifying information that can be partially disclosed incrementally during record linkage which is sufficient for high quality linkage decisions while minimizing information disclosure to acceptably low levels of privacy risk. This hypothesis is based on our preliminary research findings that indicate manual linkage decisions mainly rely on the discrepancies in potentially matched pairs (Fig B1b) rather than the raw data (Fig B1a). Given the high levels of similarity is potential match pairs, one can code and disclose only the discrepancies of the potential matches and block the rest of the information without loss to linkage quality. Thus, the specific aims of this proposal are as follows.